Using ImageMagick to Filter Page Scans
Posted: | More posts about utilities ImageMagick
I had a need to clean up some not-so-great scans of photocopies. The pages included both text and music. This made it a bit tricky to process since the music had very thin lines. I needed the text darker, but without amplifying the background noise, and this tended to fade out the lines in the staff. I was able to get good results from Paint.NET using just the Auto Levels adjustment but I had 48 pages to process and there's no way I was going to do it manually; as far as I know you can't script Paint.NET.
I briefly considered a few options, including GIMP, before re-stumbling over ImageMagick, which I've known about for ages but actually never had a need to use before. Quoting from its web site, it's "a software suite to create, edit, compose, or convert bitmap images.... [It is] typically utilized from the command line...." It handles just about every format under the sun including JPEG and PDF, which is what I needed.
There are a gazillion things you can do with it, including writing very sophisticated scripts around it, such as those included on Fred's ImageMagick Scripts page. I tried out a couple meant for thresholding (i.e. making your background fade out more while your foreground is strengthened... like boosting the contrast), including kmeansthresh, textcleaner, and 2colorthresh before finding the excellent threshold comparison study which, for my purposes, suggested that the "Local Adaptive" filter (localthresh) could be the best bet.
I cycled through a series of test runs with varying parameters (manual optimization). I settled on localthresh -n yes -m 3 -r 35 -b 20 which means:
- -n yes: "negate", since my image was black-on-white and the tool needs the inverse
- -m 3: "local mean and mean absolute deviation" mode, because the other two modes gave bad results
- -r 35: radius of 35 pixels, just larger than the thickest feature, which was some title text
- -b 20: a bias of 20, chosen empirically
The radius value matches roughly the thickness of the largest text in the page, and anything less would result in an outline (black around white regions) rather than solid lines making up the letters.
The scans were JPG format at 600dpi, about 4900x6900 pixels. I used PNG for the output files to avoid any incremental degradation, as JPG uses lossy compression (PNG is lossless). I did this as I expected to need some subsequent processing, but as it turns out this first pass was adequate (quite good, really) so that's as far as it went.
To ease printing, I wanted to combine all the images into a PDF as well. ImageMagick does that, too. Note that ImageMagick's default PDF output is uncompressed so to avoid massive file sizes I specified zip compression:
convert -compress zip *.png foo.pdf
I packaged all this up into a Python script (see below), so the whole thing was automatic (except the scanning, intermittently feeding sheets to the scanner over several hours while reading news online).
And now some before and after pictures to compare the results. Note that the main goal here was to make it easier to read the music (when reprinted) and note how much stronger the staff lines are. The text was fine either way, though it didn't hurt if it improved a bit (or lost a tiny bit of clarity, if that was the tradeoff we had to accept).
Here's a small section of music as a raw scan:

And the same section after filtering:

For comparison here's a small bit of text:
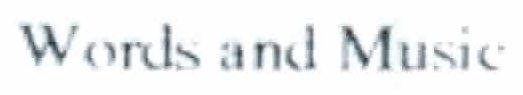
And the filtered output:
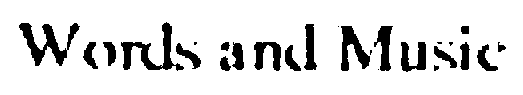
Here's the script. Note that it is meant for Linux, mainly because of the "localthresh" script which uses Bash shell syntax. The script assumes you have ImageMagick installed and that you have downloaded localthresh into the current directory, and did chmod +x localthresh to make it executable. Make appropriate changes for other systems and note that as usual Windows is a second class citizen.
To invoke it, make sure to escape any wildcards with single quotes, as in ./scans2pdf.py '/home/foo/*.jpg' or the shell will expand them and
#!/usr/bin/env python '''Mass filtering of page scans to improve text quality using ImageMagick.''' import argparse import glob import os import shutil import tempfile def main(args): tempdir = tempfile.mkdtemp() try: files = [] for arg in args.input: files.extend(glob.glob(arg)) for name in sorted(files): convert(name, tempdir) if os.path.exists(args.output): if args.force: os.remove(args.output) else: sys.exit('Output file "%s" exists. Use -f or --force to overwrite.') os.system('convert %s/*.png -compress zip %s' % (tempdir, args.output)) finally: shutil.rmtree(tempdir) def convert(filename, tempdir): inf = os.path.splitext(os.path.basename(filename))[0] outf = os.path.join(tempdir, 'out-' + inf + '.png') os.system('./localthresh -n yes -m 3 -r 35 -b 20 %s %s' % (inf, outf)) if __name__ == '__main__': parser = argparse.ArgumentParser( description='Mass filtering of page scans using ImageMagick.') parser.add_argument('input', nargs='+', help='Files or glob pattern(s) for input file, e.g. /home/foo/scan-*.jpg') parser.add_argument('-o', '--output', default='output.pdf', help='Name of output file, default "%(default)s"') parser.add_argument('-f', '--force', action='store_true', help='Overwrite if output file already exists.') args = parser.parse_args() main(args)
All this is offered up primarily for beginners looking for examples, rather than as a paragon of image processing virtuosity. Experts could do better, but this did just fine for my purposes and I hope some part of it helps out someone else.